by Soontaek Lim
Share
by Soontaek Lim

In the ever-evolving landscape of artificial intelligence and machine learning, the quest for more efficient and effective model-tuning methods is constant. One intriguing approach gaining attention is LoRA, short for Low-Rank Adaptation. LoRA offers a promising solution for improving the performance of models, particularly in resource-constrained environments or when dealing with large-scale datasets.
The core of the LoRA methodology mentioned is the Low-Rank Decomposition. Literally, it involves decomposing large-dimensional matrix operations into lower dimensions. Let’s consider the Self-attention operation. In Self Attention, we need to construct Q, K, and V using matrix operations. The matrices W used to create Q, K, and V are very high-dimensional. This is unavoidable due to the large dimensionality of the input. The idea here is to decompose these high-dimensional matrices into lower dimensions.
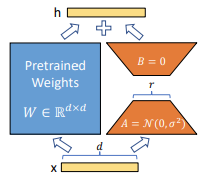
The left blue represents the original high-dimensional matrix. It has dimensions of dd, where d is the dimensionality of the input features. On the other hand, the right orange represents the Low-Rank Decomposed matrix. It consists of two matrices, A and B, each with dimensions of dr and r*d, respectively. Here, if r is much smaller than d (for example, 1 or 2), then there will be very few operations in the orange matrix. In LoRA, the blue parameters are the pre-trained weights, so they remain fixed, while only the orange parameters are added and trained for the downstream task.
Empirical Experiments

The figure above compares the GLUE benchmark performance of RoBERTa, DeBERTa with Fine-Tuning (FT), and other PEFT methods (BitFit, Adpt) against LoRA. It’s intriguing to note that LoRA achieves better performance using fewer parameters compared to other PEFT methods. What’s more fascinating is that in some cases, LoRA outperforms traditional Fine-Tuning methods.
Fine-Tuning has long been a staple in the machine learning community for adapting pre-trained models to specific downstream tasks. However, it often requires extensive computational resources and can lead to overfitting, especially when dealing with large models and limited datasets.
In contrast, LoRA takes a different approach by leveraging Low-Rank Decomposition to optimize the tuning process. By decomposing high-dimensional matrices into lower dimensions, LoRA effectively reduces the computational burden while preserving or even enhancing model performance.
Pros and Cons
Even with its strengths, LoRA has its own set of pros and cons. First, the LoRA paper mentions three advantages.
The first advantage is reduced memory and storage usage. This is an aspect that becomes immediately apparent once you understand the LoRA method. LoRA does not train on the existing pre-trained parameters, so there’s no need to store these parameters in the optimizer. As a result, depending on the dimensionality achieved through Low-Rank Decomposition, approximately two-thirds of the VRAM usage can be reduced. Additionally, the checkpoint size can also be significantly reduced.
The second advantage is lower inference cost. This is because LoRA has separate parameters for each task and switches computations accordingly based on the task.
The third advantage is reduced training time. Based on the GPT3 175B model, it’s reported to be 25% faster. This is because there’s no need to compute gradients for most pre-trained parameters.
On the other hand, the LoRA paper also points out limitations. One notable limitation is the inability to mix various tasks and compose batches. This is due to the method of using different LoRA parameters for each task. In other words, separate datasets need to be composed for each task, requiring separate fine-tuning processes.
Conclusion
In the pursuit of more efficient and effective model-tuning techniques, LoRA stands out as a promising approach. By leveraging localized representations and targeted parameter updates, LoRA unlocks new levels of efficiency and performance in model adaptation. Whether in research laboratories, industrial settings, or everyday applications, the principles of LoRA offer valuable insights into the future of machine learning optimization. In essence, LoRA represents a paradigm shift in how we approach model tuning, emphasizing efficiency, adaptability, and performance. As the field of machine learning continues to evolve, innovations like LoRA pave the way for more intelligent, resource-efficient, and impactful AI systems.
Reference: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS



