by Sally Bo Hatter
Share
by Sally Bo Hatter
")
Einführung
In der sich schnell entwickelnden Welt des Datenmanagements stellt Delta Lake einen transformativen Fortschritt dar, der die Handhabung und Verarbeitung großer Datenmengen mit Apache Spark optimiert. Als Open-Source-Speicherschicht, die von den Schöpfern von Spark entwickelt wurde, verbessert Delta Lake die Zuverlässigkeit, Leistung und Verwaltung von Daten und macht Data Lakes in Unternehmen einfacher und robuster. Die Verwaltung komplexer Datenpipelines mit herkömmlichem Spark kann aufgrund ineffizienter Upserts, komplexer Zeitreisen und Schema-Inkonsistenzen eine Herausforderung darstellen. Delta Lake löst diese Probleme mit Funktionen, die den Betrieb rationalisieren und eine hohe Datenqualität gewährleisten. Seine Medaillon-Architektur wirkt wie eine Reihe von Toren, die sicherstellen, dass nur saubere Daten die Rohdaten-, Kuratierungs- und Serving-Ebenen durchlaufen. Die Durchsetzung von Schemata verhindert, dass unsaubere Daten Ihre Pipeline verunreinigen, während die eingebaute Versionierung wie eine Zeitmaschine funktioniert, die eine einfache Prüfung und ein Rollback zu früheren Datenzuständen ermöglicht. Delta Lake bietet außerdem effiziente Merge-Operationen, die die Datenintegration vereinfachen und die Komplexität und den Zeitaufwand für Upserts reduzieren. Leistungsverbesserungen wie Z-Ordering optimieren die Speicherung, beschleunigen Abfragen und senken die Kosten. Die Verwaltung von Metadaten strukturiert Informationen effektiv, und der Vakuum-Befehl hilft dabei, Daten zu organisieren und relevant zu halten. Durch die Integration von Delta Lake mit Apache Spark können Dateningenieure skalierbare, zuverlässige und effiziente Datenpipelines erstellen. Diese Integration sorgt für eine höhere Datenqualität, optimierte Speicherung, geringere Betriebskosten und eine agilere Dateninfrastruktur und macht Spark zu einem leistungsfähigeren Werkzeug für moderne Datenherausforderungen.
Einführung in Delta Lake
Delta Lake, eine Open-Source-Speicherschicht von Databricks, wurde Anfang 2019 eingeführt. Sie wurde entwickelt, um die Zuverlässigkeit und Leistung von Data Lakes zu verbessern und lässt sich nahtlos mit Apache Spark integrieren.
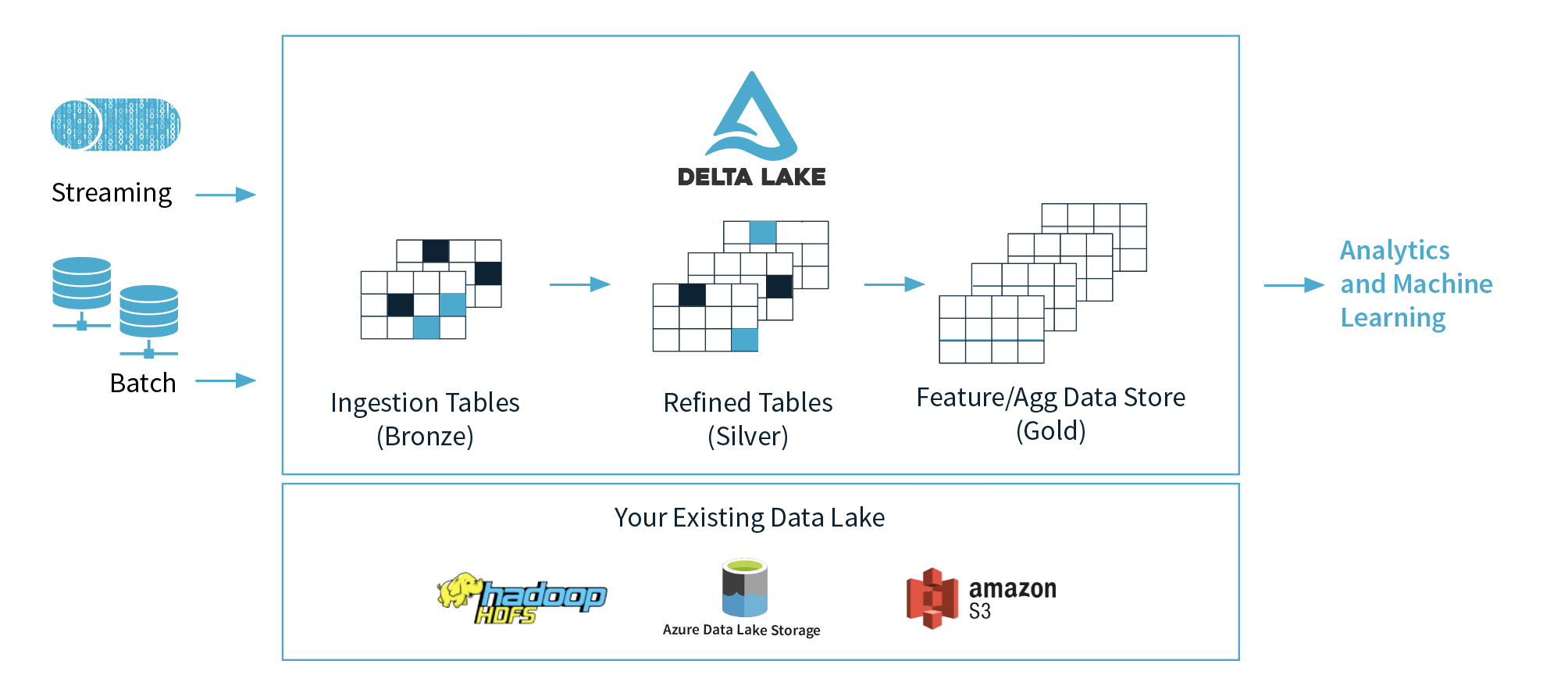
Warum Delta Lake verwenden?
Delta Lake löst mehrere gängige Probleme bei der Datenverwaltung und -verarbeitung:
- Open Source: Angetrieben von Beiträgen der Community und unterstützt von Databricks mit offenen Standards und Protokollen.
- ACID-Transaktionen: Sorgt für zuverlässige und konsistente Datenoperationen mit starker Isolierung.
- Zeitreise: Ermöglicht die Abfrage von früheren Datenversionen für Audits und Rollbacks.
- Schema-Entwicklung: Unterstützt Schemaänderungen ohne Unterbrechung des laufenden Betriebs.
- Gleichzeitige Schreibvorgänge: Ermöglicht das gleichzeitige Schreiben von Daten, was für umfangreiche Anwendungen entscheidend ist.
- Optimierung der Leistung: Funktionen wie Z-Ordering und das Überspringen von Daten verbessern die Abfragegeschwindigkeit.
- Skalierbare Metadaten: Verwalten Sie umfangreiche Datensätze mit Milliarden von Partitionen und Dateien.
- Vereinheitlichtes Batch/Streaming: Ermöglicht eine Exact-once-Semantik für Batch- und Streaming-Daten.
- Audit-Verlauf: Bietet einen vollständigen Prüfpfad mit detaillierten Protokollen aller Datenänderungen.
- DML-Operationen: Bietet flexible APIs (SQL, Scala/Java, Python) für Datenmanipulationsaufgaben.
Einführung in Apache Spark
Apache Spark ist eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen mit integrierten Modulen für Streaming, SQL, maschinelles Lernen und Graphverarbeitung. Die verteilten Rechenfunktionen von Spark machen es zu einem leistungsstarken Werkzeug für die schnelle und effiziente Verarbeitung großer Datenmengen. Zu den wichtigsten Funktionen von Spark gehören die In-Memory-Datenverarbeitung, die erweiterte Abfrageoptimierung und die Unterstützung verschiedener Datenquellen und -formate. Spark Core: Verwaltet die Planung von Aufgaben und die Speicherverwaltung.
- Spark SQL: Bietet Funktionen zur Datenabfrage.
- Spark Streaming: Verarbeitet Daten in Echtzeit.
- MLlib: Für maschinelles Lernen.
- GraphX: Für die Verarbeitung von Graphen.

Verbesserung von Spark mit Delta Lake
Delta Lake erweitert Apache Spark durch die Integration einer leistungsstarken Schicht, die die Datenverwaltung und -verarbeitung verbessert. Ursprünglich exklusiv für Databricks, ist es jetzt Open Source unter der Apache License V2. Delta Lake lässt sich nahtlos in bestehende Speichersysteme integrieren und bietet eine einheitliche Plattform für die Batch- und Streaming-Datenverarbeitung, die Datenkonsistenz, eine einfache Schemaverwaltung und die Möglichkeit zur Abfrage historischer Datenversionen gewährleistet. Im Folgenden finden Sie einen kurzen Überblick darüber, wie Delta Lake Spark erweitert und wie der Datenfluss und die Interaktionspunkte aussehen:
- Daten-Ingestion:
- Quellen: Delta Lake ermöglicht die nahtlose Aufnahme von Daten aus verschiedenen Quellen, einschließlich Cloud Object Stores, Datenbanken und Streaming-Plattformen.
- Integration: Die Daten werden in Delta Lake-Tabellen eingelesen, die sowohl für Batch- als auch für Streaming-Operationen optimiert sind. Diese Integration unterstützt die Aufnahme von Daten mit hohem Durchsatz und minimaler Latenz.
- Datenverarbeitung:
- Spark-Integration: Sobald sich die Daten in Delta Lake-Tabellen befinden, verarbeitet Spark sie effizient mit seinen verteilten Rechenfunktionen.
- ACID-Transaktionen: Delta Lake bietet ACID-Transaktionen, um die Datenkonsistenz während der Verarbeitung sicherzustellen. Dies garantiert, dass alle Vorgänge korrekt abgeschlossen werden und im Falle von Fehlern Rollback-Funktionen zur Verfügung stehen.
- Datenverwaltung:
- Schema-Entwicklung: Delta Lake vereinfacht die Schemaverwaltung, indem es Schemaänderungen ohne Unterbrechung des laufenden Betriebs ermöglicht. Diese Flexibilität ist entscheidend für die Anpassung an sich entwickelnde Datenstrukturen.
- Zeitreise: Ermöglicht Benutzern den Zugriff auf und die Abfrage von früheren Datenversionen und erleichtert so Audits, Rollbacks und die Analyse historischer Daten.
- Daten abfragen:
- Spark SQL: Benutzer können Spark SQL nutzen, um komplexe Abfragen auf Delta Lake-Tabellen auszuführen. Die Optimierungen von Delta Lake, wie z.B. das Überspringen von Daten und Z-Ordering, verbessern die Abfrageleistung und reduzieren die Ausführungszeiten.
Delta Lake erweitert die Fähigkeiten von Apache Spark, indem es ein robustes Framework für die Datenverwaltung bietet. Seine Funktionen – ACID-Transaktionen, Schema-Evolution und Zeitreisen – verbessern die Leistung, Datenzuverlässigkeit und Flexibilität von Spark. Diese Integration stellt sicher, dass Spark-Anwender von einer verbesserten Datenkonsistenz, optimierten Schemaanpassungen und leistungsstarken Abfragefunktionen profitieren.

Praktisches Beispiel: Delta Lake mit Apache Spark
Dieser Abschnitt enthält ein praktisches Beispiel für die Verwendung von Delta Lake mit Apache Spark. Detaillierte Anweisungen zur Einrichtung und weitere Informationen finden Sie in der Delta Lake-Dokumentation. Der Einfachheit halber werden wir Python verwenden und anhand von Notebook-Zellen demonstrieren, wie Sie die Funktionen von Delta Lake nutzen können.
Einrichtung und Initialisierung
Um Delta Lake mit Apache Spark zu integrieren, haben Sie mehrere flexible Möglichkeiten:
- Interactive Shell: Verwenden Sie PySpark oder die Spark Scala-Shell für die direkte Interaktion. Sie können PySpark mit Delta Lake mit pip oder die Scala-Shell mit bin/spark-shell von Spark einrichten, beide mit Delta Lake-Abhängigkeiten und -Konfigurationen.
- Projekt einrichten: Erstellen Sie ein Projekt mit Delta Lake unter Verwendung von Maven oder SBT für Scala/Java, oder konfigurieren Sie Python-Projekte mit pip und delta-spark. Dieses Setup ermöglicht eine skalierbare Entwicklung und Integration in größere Anwendungen.
Installation der Bibliothek für die Demo
Für die Demo haben wir uns entschieden, den Code in einer lokalen Jupyter Notebook-Umgebung auszuführen. Bitte installieren Sie die erforderlichen Bibliotheken mit Python, um die Demo einzurichten: !pip install pyspark delta-spark Vergewissern Sie sich, dass das Jupyter-Notebook lokal installiert ist und geben Sie dann im Terminal ein: jupyter notebook Dieser Befehl richtet PySpark und Delta Lake für die interaktive Nutzung ein und stellt sicher, dass Sie die für die Datenverarbeitung und -verwaltung erforderlichen Tools in Ihrer Umgebung haben. 4.3 Einrichten von Spark mit Delta Lake Um Delta Lake mit Apache Spark in Ihrer Python-Umgebung zu verwenden, müssen Sie zunächst eine SparkSession mit den erforderlichen Delta Lake-Konfigurationen initialisieren. Diese Einrichtung ermöglicht es Ihnen, die Funktionen von Delta Lake wie ACID-Transaktionen und Schemaentwicklung in Ihren Spark-Anwendungen zu nutzen. Hier erfahren Sie, wie Sie Spark mit Delta Lake konfigurieren können:
")
Laden von Beispieldaten
Dieses Codeschnipsel liest eine CSV-Datei in einen Spark DataFrame ein, wobei das Schema abgeleitet und die Kopfzeilen einbezogen werden. Anschließend zeigt er die ersten 5 Zeilen des DataFrame an und liefert eine Zusammenfassung der Statistiken des Datensatzes.
")
Schreiben und Lesen von Daten mit Delta Lake
In diesem Abschnitt wird gezeigt, wie Sie Daten in eine Delta Lake-Tabelle schreiben und dann wieder zurücklesen. Der Code speichert den DataFrame in einer Delta Lake-Tabelle unter dem angegebenen Pfad und liest ihn dann in einen neuen DataFrame zurück und zeigt die Ergebnisse an.
")
Hinzufügen und Lesen neuer Daten mit der Schemaverwaltung
In diesem Abschnitt wird gezeigt, wie Sie neue Daten zu einer Delta Lake-Tabelle hinzufügen und Schemaänderungen handhaben können. Das folgende Codeschnipsel zeigt, wie Sie neue Daten zu einer Delta Lake-Tabelle hinzufügen und gleichzeitig die Schemaentwicklung verwalten können. Es fügt neue Datensätze an die Tabelle an und stellt die Konsistenz sicher, indem es die aktualisierten Daten nach jeder Transaktion anzeigt.
")
")
Hinzufügen neuer Spalten und Schemaentwicklung
In diesem Abschnitt wird erläutert, wie Sie einer bestehenden Delta Lake-Tabelle neue Spalten hinzufügen und ihr Schema aktualisieren. Mit der Option mergeSchema wird das Schema nahtlos weiterentwickelt, so dass neue Spalten integriert werden können, ohne die vorhandenen Daten zu beeinträchtigen.

Zeitreise und Versionswiederherstellung
Dieser Abschnitt demonstriert die Zeitreisefunktion von Delta Lake. Durch die Angabe von versionAsOf oder timestampAsOf können Sie frühere Versionen der Tabelle abfragen und wiederherstellen und so sicherstellen, dass Daten aus früheren Zuständen wiederhergestellt oder geprüft werden können.
")

Optimieren mit Z-Ordering
In diesem Abschnitt verwenden wir Z-Ordering zur Optimierung der Delta-Tabelle. Z-Ordering ist eine Technik in Delta Lake, die die Abfrageleistung verbessert, indem zusammengehörige Daten im Speicher zusammengelegt werden. Der Befehl optimize().executeZOrderBy(„PickupZip“) reorganisiert die Datendateien, um die Zugriffsmuster für Abfragen zu optimieren, die nach PickupZip filtern. Eine visuelle Erklärung der Z-Ordnung und ihrer Auswirkungen auf die Abfrageeffizienz finden Sie in der nebenstehenden Abbildung.
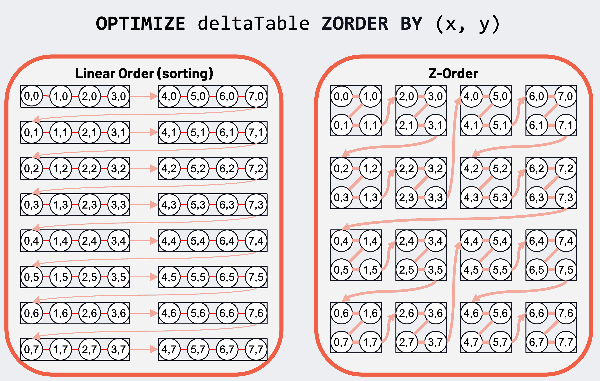
Nachfolgend finden Sie dieses Codeschnipsel:

Streaming-Daten und Upsert-Operationen
In diesem Abschnitt zeigen wir Ihnen, wie Sie mit Delta Lake Streaming-Daten verarbeiten und Upsert-Operationen durchführen können.
- Streaming-Datenquelle: Wir richten eine Streaming-Quelle mit spark.readStream.format(„rate“).load() ein, die einen Datenstrom simuliert. Diese Daten werden dann in die Delta-Tabelle mit einem Checkpoint-Verzeichnis geschrieben, um Fehlertoleranz und Konsistenz zu gewährleisten.
- Streaming-Daten lesen: Die Streaming-Daten werden aus der Delta-Tabelle gelesen und in der Konsole angezeigt. Diese Einstellung ermöglicht Aktualisierungen und Überwachung in Echtzeit.
- Upsert Operation: Wir verwenden die Zusammenführungsfunktion von Delta Lake, um eine Upsert-Operation durchzuführen, die bestehende Datensätze aktualisiert oder neue Datensätze auf der Grundlage einer passenden Bedingung einfügt. Dieser Vorgang ist wichtig, um aktuelle und genaue Daten in Echtzeitszenarien zu erhalten.
- Datenlöschung und -verdichtung: Wir demonstrieren die Datenlöschung und Dateikompaktierung mit deltaTable.delete() und deltaTable.vacuum(), die zur Verwaltung der Datengröße und Leistung beitragen.

Um ein vollständiges Verständnis zu erhalten, sehen Sie sich das mitgelieferte Diagramm an, das den Datenfluss und die Interaktion zwischen Streaming-Datenquellen und Delta Lake veranschaulicht.
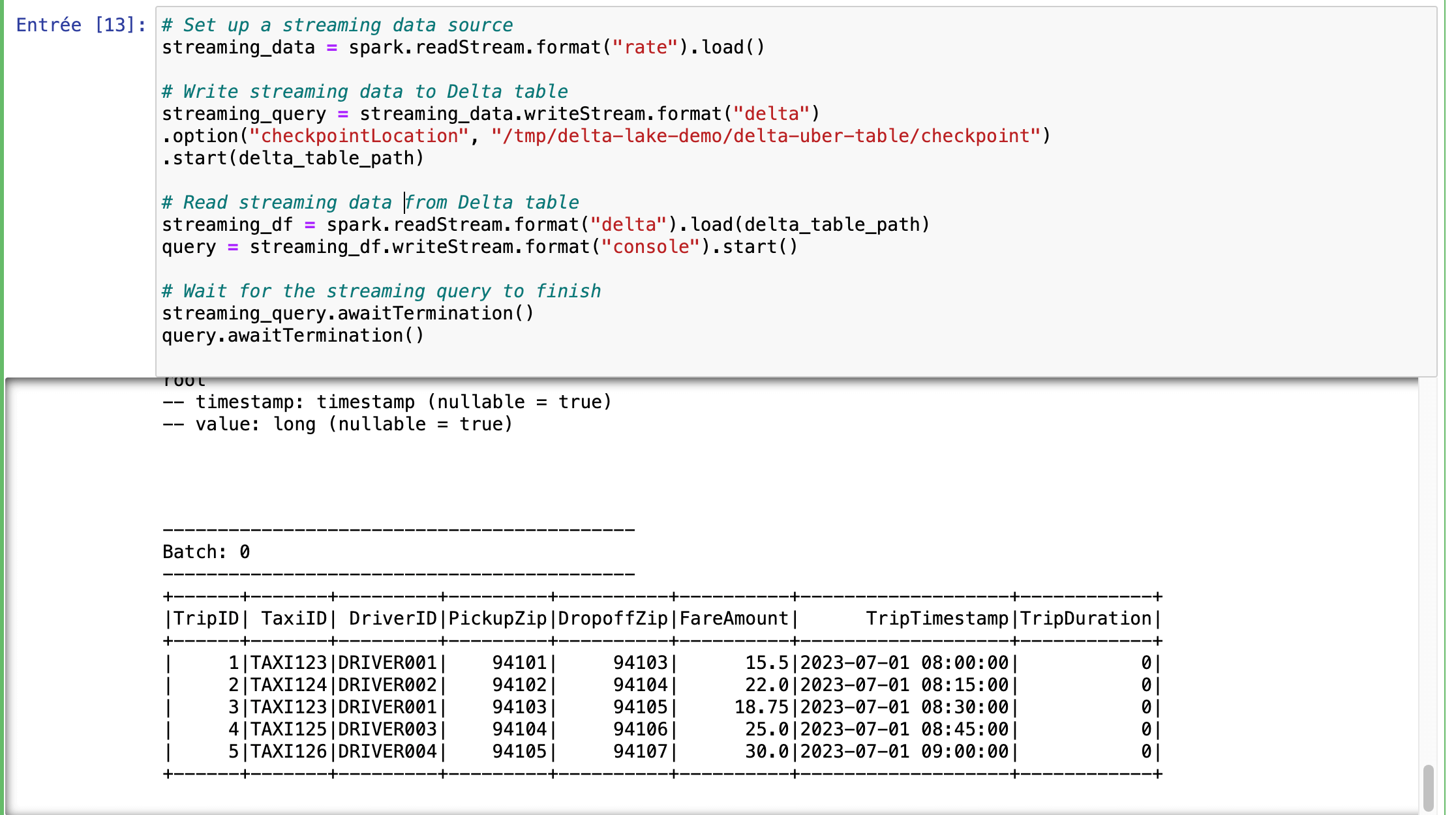
spark_delta_1
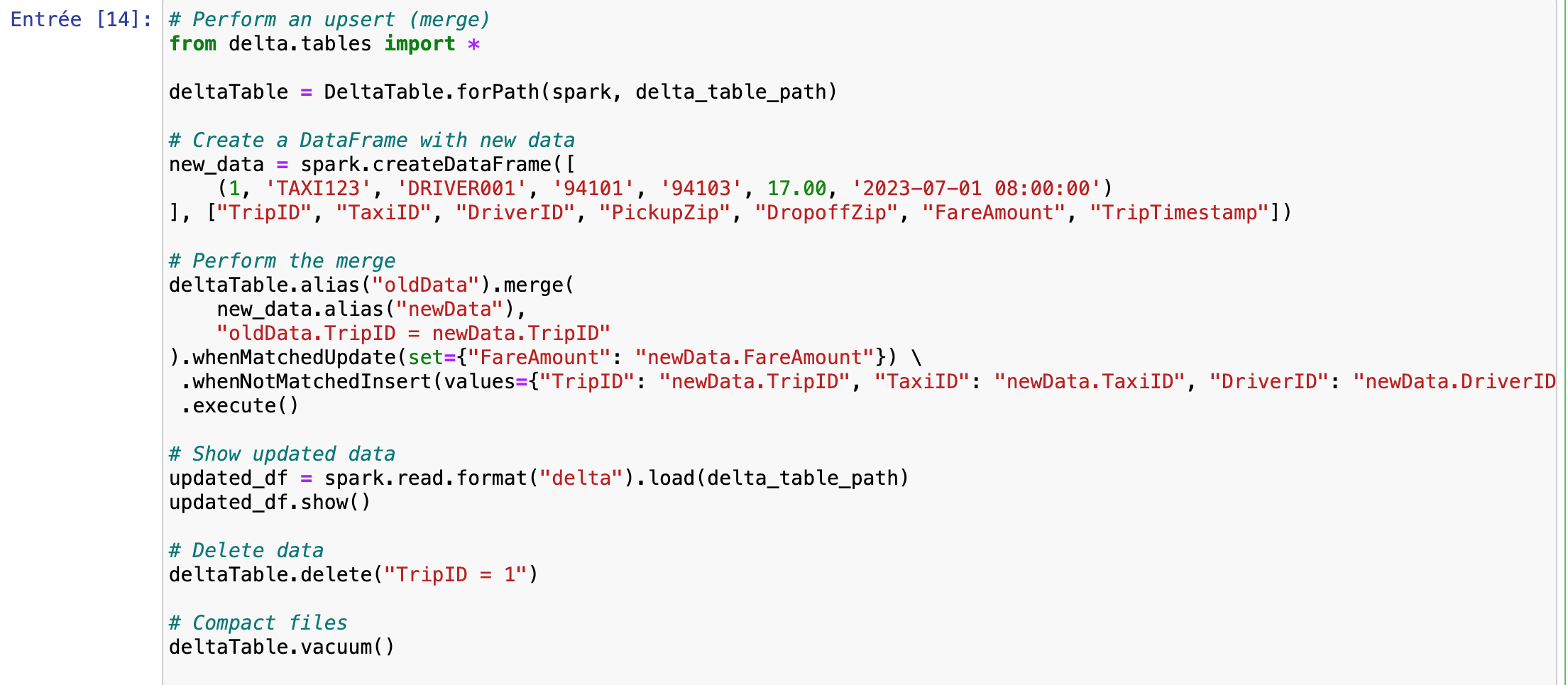
Der Upsert-Vorgang war erfolgreich, wie die aktualisierte erste Zeile der Daten zeigt. Außerdem wurden die veralteten Dateien durch die Vakuumoperation effektiv bereinigt.

Wir können nun den Löschvorgang überprüfen, indem wir die Daten aus dem Stream abrufen und sicherstellen, dass die zuvor gelöschte erste Zeile nicht mehr erscheint.

Deltatabelle anzeigen – Verlauf und Aufräumen
In diesem Abschnitt wird gezeigt, wie Sie die historischen Änderungen in einer Delta-Tabelle anzeigen und eine Datenbereinigung durchführen können.

Mit diesem Code können Sie die Änderungshistorie der Delta-Tabelle einsehen, was Ihnen hilft, Änderungen zu verfolgen und die Entwicklung Ihrer Daten zu verstehen. Die Vakuum-Operation wird verwendet, um alte, nicht mehr benötigte Datendateien zu bereinigen, wobei nur die Dateien der letzten angegebenen Anzahl von Stunden (168 Stunden = 7 Tage) erhalten bleiben. Wir werden untersuchen, wie Delta Lake Metadaten für Skalierbarkeit und Auditing handhabt. Delta Lake führt ein detailliertes Protokoll aller Änderungen an Ihren Daten, das als JSON-Dateien in einem Verzeichnis namens _delta_log gespeichert wird. In diesen Protokollen werden alle Änderungen, Hinzufügungen und Löschungen protokolliert, so dass Sie einen umfassenden Überblick über alle Transaktionen erhalten. Anhand dieser Protokolle können Sie überprüfen, wie effizient Delta Lake Metadaten im großen Maßstab verwaltet und dabei sowohl Skalierbarkeit als auch Nachvollziehbarkeit gewährleistet. Ich mache einen Screenshot, der das Verzeichnis und diese Protokolldateien zeigt, um zu veranschaulichen, wie Delta Lake die Änderungsdetails für eine robuste Datenverwaltung erfasst und organisiert.
Speicher Core Unit
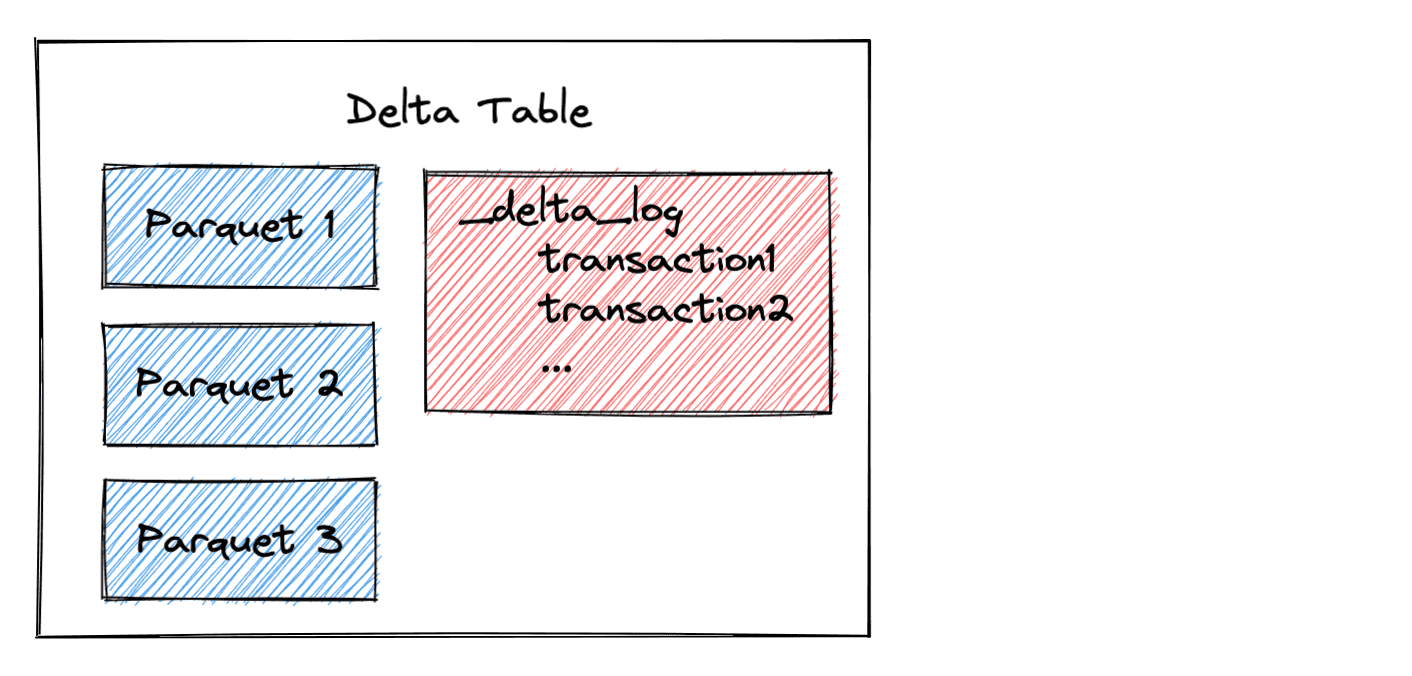
In Delta Lake ist eine Tabelle eine Sammlung von Daten, die in einem Schema und einer Verzeichnisstruktur organisiert sind. Sie stellt die grundlegende Einheit der Speicherung dar. Hier ist es die lokale Darstellung der Delta-Tabelle:

Abschließende Zusammenfassung
Der Übergang von Delta Lake zu Open Source ist ein wichtiger Meilenstein, der das Potenzial für eine breitere Integration und Innovation freisetzt. Durch die Unterstützung verschiedener Speichersysteme wie S3 und ADLS und mehrerer Programmiersprachen, darunter Java, Python, Scala und SQL, erhöht Delta Lake seine Vielseitigkeit. Seine Kompatibilität mit Hive Metastore und die Fähigkeit, sowohl Batch- als auch Streaming-Daten zu verwalten, festigen seine Rolle in modernen Datenarchitekturen. Der Open-Source-Charakter von Delta Lake ebnet den Weg für neue Konnektoren, wie z.B. die mit Presto, und fördert so eine tiefere Integration mit verschiedenen Technologien. Dieser Schritt verstärkt nicht nur das Engagement der Community, sondern beschleunigt auch die Entwicklung neuer Funktionen und Verbesserungen. Obwohl Delta Lake nicht für OLTP entwickelt wurde und einige Einschränkungen bei älteren Spark-Versionen und bestimmten Dateiformaten aufweist, bieten die Fortschritte von Delta Lake bei der Durchsetzung von Schemata, der Konsistenz und der Isolierung eine robuste Lösung für Datenqualität und -management. Das wachsende Ökosystem und die expandierende Community sorgen dafür, dass Delta Lake sich ständig weiterentwickelt und verbesserte Funktionen bietet, was es zu einem unschätzbaren Vorteil für künftige Herausforderungen im Data Engineering macht.



