by Sally Bo Hatter
Share
by Sally Bo Hatter

In der sich ständig weiterentwickelnden Landschaft der künstlichen Intelligenz und des maschinellen Lernens ist man ständig auf der Suche nach effizienteren und effektiveren Methoden zur Modellabstimmung. Ein faszinierender Ansatz, der an Aufmerksamkeit gewinnt, ist LoRA, kurz für Low-Rank Adaptation. LoRA bietet eine vielversprechende Lösung zur Verbesserung der Leistung von Modellen, insbesondere in ressourcenbeschränkten Umgebungen oder beim Umgang mit großen Datensätzen.
Der Kern der erwähnten LoRA-Methode ist die Low-Rank-Zerlegung. Wörtlich bedeutet dies, dass großdimensionale Matrixoperationen in niedrigere Dimensionen zerlegt werden. Betrachten wir die Operation Self-attention. Bei Self-Attention müssen wir Q, K und V mithilfe von Matrixoperationen konstruieren. Die Matrizen W, die zur Erstellung von Q, K und V verwendet werden, sind sehr hochdimensional. Dies ist aufgrund der großen Dimensionalität der Eingabe unvermeidlich. Die Idee hier ist, diese hochdimensionalen Matrizen in niedrigere Dimensionen zu zerlegen.
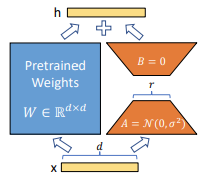
Das linke Blau stellt die ursprüngliche hochdimensionale Matrix dar. Sie hat die Dimensionen dd, wobei d die Dimensionalität der eingegebenen Merkmale ist. Die rechte orangefarbene Matrix hingegen steht für die Low-Rank Decomposed Matrix. Sie besteht aus zwei Matrizen, A und B, mit den Dimensionen dr bzw. r*d. Wenn r viel kleiner ist als d (z.B. 1 oder 2), gibt es nur sehr wenige Operationen in der orangefarbenen Matrix. In LoRA sind die blauen Parameter die vortrainierten Gewichte, sie bleiben also fest, während nur die orangefarbenen Parameter hinzugefügt und für die nachfolgende Aufgabe trainiert werden.
Empirische Experimente

Die obige Abbildung vergleicht die GLUE Benchmark-Leistung von RoBERTa, DeBERTa mit Fine-Tuning (FT) und anderen PEFT-Methoden (BitFit, Adpt) mit LoRA. Es ist faszinierend festzustellen, dass LoRA im Vergleich zu anderen PEFT-Methoden mit weniger Parametern eine bessere Leistung erzielt. Noch faszinierender ist, dass LoRA in einigen Fällen die traditionellen Fine-Tuning-Methoden übertrifft. Fine-Tuning ist in der Gemeinschaft des maschinellen Lernens seit langem ein fester Bestandteil, um vortrainierte Modelle an spezifische nachgelagerte Aufgaben anzupassen. Es erfordert jedoch oft umfangreiche Rechenressourcen und kann zu einer Überanpassung führen, insbesondere wenn es sich um große Modelle und begrenzte Datensätze handelt. Im Gegensatz dazu verfolgt LoRA einen anderen Ansatz, indem es die Low-Rank-Zerlegung zur Optimierung des Abstimmungsprozesses einsetzt. Durch die Zerlegung hochdimensionaler Matrizen in niedrigere Dimensionen reduziert LoRA effektiv den Rechenaufwand, während die Modellleistung erhalten bleibt oder sogar verbessert wird.
Pro und Kontra
Trotz seiner Stärken hat LoRA eine Reihe von Vor- und Nachteilen. Zunächst werden in dem LoRA-Papier drei Vorteile genannt. Der erste Vorteil ist die geringere Nutzung von Arbeitsspeicher und Speicherplatz. Dieser Aspekt wird sofort deutlich, wenn Sie die LoRA-Methode verstehen. LoRA trainiert nicht auf den vorhandenen vortrainierten Parametern, so dass diese Parameter nicht im Optimierer gespeichert werden müssen. Je nach Dimensionalität, die durch Low-Rank Decomposition erreicht wird, können so etwa zwei Drittel der VRAM-Nutzung eingespart werden. Darüber hinaus kann auch die Größe der Prüfpunkte erheblich reduziert werden. Der zweite Vorteil sind die geringeren Inferenzkosten. Das liegt daran, dass LoRA für jede Aufgabe separate Parameter hat und die Berechnungen entsprechend der Aufgabe umschaltet. Der dritte Vorteil ist die geringere Trainingszeit. Basierend auf dem GPT3 175B Modell ist es Berichten zufolge 25% schneller. Das liegt daran, dass für die meisten vortrainierten Parameter keine Gradienten berechnet werden müssen. Auf der anderen Seite weist das LoRA-Papier auch auf Einschränkungen hin. Eine bemerkenswerte Einschränkung ist die Unfähigkeit, verschiedene Aufgaben zu mischen und Stapel zu bilden. Dies ist auf die Methode zurückzuführen, für jede Aufgabe unterschiedliche LoRA-Parameter zu verwenden. Mit anderen Worten: Für jede Aufgabe müssen separate Datensätze zusammengestellt werden, was separate Feinabstimmungsprozesse erfordert.
Fazit
Auf der Suche nach effizienteren und effektiveren Techniken zur Modellanpassung erweist sich LoRA als vielversprechender Ansatz. Durch die Nutzung lokalisierter Repräsentationen und gezielter Parameteraktualisierungen eröffnet LoRA neue Ebenen der Effizienz und Leistung bei der Modellanpassung. Ob in Forschungslabors, in der Industrie oder bei alltäglichen Anwendungen, die Prinzipien von LoRA bieten wertvolle Einblicke in die Zukunft der Optimierung des maschinellen Lernens. Im Wesentlichen stellt LoRA einen Paradigmenwechsel in der Art und Weise dar, wie wir an die Modellanpassung herangehen, wobei Effizienz, Anpassungsfähigkeit und Leistung im Vordergrund stehen. Da sich der Bereich des maschinellen Lernens ständig weiterentwickelt, ebnen Innovationen wie LoRA den Weg für intelligentere, ressourceneffizientere und wirkungsvollere KI-Systeme.
Referenz: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS


